


構造化データとは
構造化データとは、Webサイトが持つ意味をコンピューターが理解しやすいものにするセマンティックWebを実現するための手段のひとつです。
検索エンジンは、HTMLで書かれている文字列や画像が何を意味しているか理解できません。そこで、ロボットでもその内容が理解できるように、HTMLで書かれている情報が何を表しているのかを意味づけしたものが構造化データです。
ロボットがHTMLに書かれている内容を正しく解釈するのを助けることで、より有用な検索結果をユーザーに提供することができるようになるのです。
そのため、構造化データの記述はSEO対策を考える上で重要視されているもののひとつとなっています。
構造化データを使うメリット・デメリット
構造化データを記述することの具体的なメリットは、先述したように検索エンジンがサイトの内容を適切に認識できるようになることです。
構造化データのマークアップによって直接検索順位のアップにつながるというわけではありません。
構造化データのマークアップをすることで検索エンジンがサイトの内容を適切に認識することができるようになり、結果としてSEOの強化につながるということです。
それでは、検索エンジンがサイトの内容を適切に認識することで、何ができるのかについて詳しく解説していきたいと思います。
1.リッチスニペットを表示させることができる
「リッチスニペット」とは、検索エンジンで検索をしたときに、ユーザーが最適なページを判断するのを助けるために視覚的にページ内容を表示させる機能のことです。
スニペットとは、検索結果のサイトタイトル下部に表示される要約(description)やページ内の文言の抜粋などからなるサイト情報です。
リッチスニペットはこのスニペットに加えて画像や評価などの情報を併せて表示されているもののことです。
現在Googleがリッチスニペットをサポートしているコンテンツは以下の7つです。
- 人物
- 商品
- 会社と組織
- レビュー
- レシピ
- イベント
- 音楽
リッチスニペットの例をいくつか挙げてみました。
レビューの例
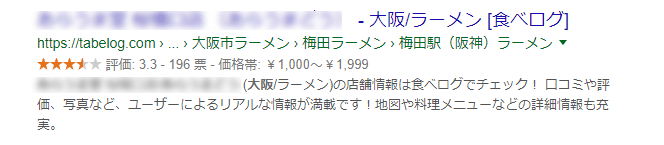
レシピの例

イベントの例

2.ページ内のコンテンツがナレッジグラフに表示される
「ナレッジグラフ」とは、Googleの検索アルゴリズムの1つで、ただ単に検索されたキーワードを含む情報を検索結果に表示するのではなく、その検索キーワードに関するそれぞれの情報の関係性や属性を認識・把握した上で、まとめて表示する仕組みのことです。
そしてナレッジグラフによって表示されるボックスのことを「ナレッジカード」または「ナレッジパネル」と呼びます。
下記図の赤枠部分のものがナレッジグラフです。
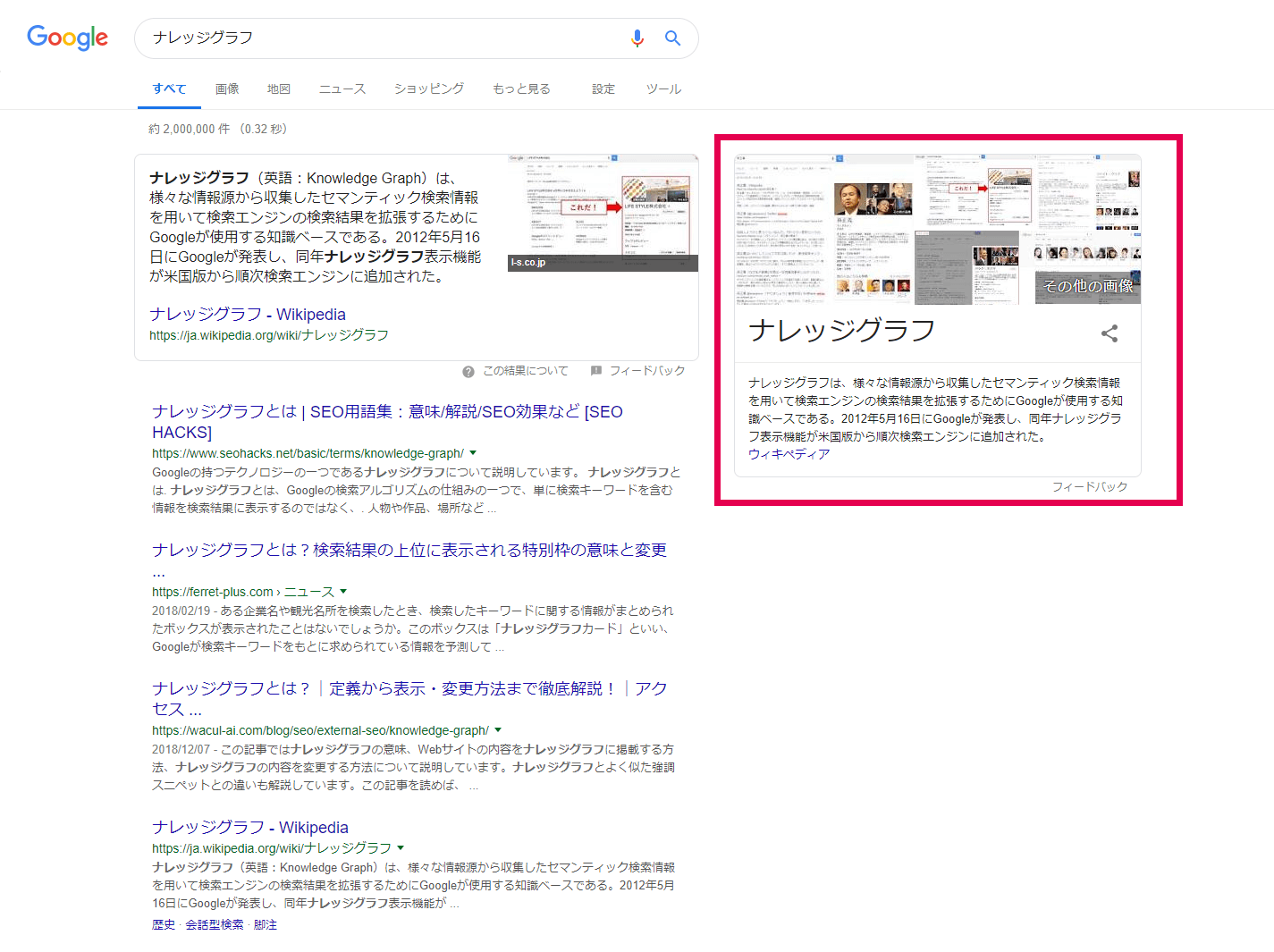
構造化データを記述するメリットとしては、このようにGoogleの検索結果に表示されたときに多くのユーザーの目に触れることになるという点が挙げられます。
デメリット
デメリットとしては、構造化データを記述することでソースのデータサイズが大きくなってしまったり、そもそも記述するこで工数が増えるという点が挙げられます。
また、ナレッジグラフに関しては、主にGoogle+やWikipediaがその情報源として使われているため、記述したとしても、現時点では必ずしもナレッジグラフとして表示されるわけではないという点です。
構造化データの書き方
構造化データは「シンタックス」と「ボキャブラリー」の2つから成り立っています。
シンタックスとは構造化データの書き方のことで、代表的なものが以下の3つです
- JSON-LD(scriptタグ内にまとめて記述)
- microdata(HTMLタグに直接記述)
- RDFa(HTMLタグに直接記述)
構造化データを構成するもう一つの要素であるボキャブラリーは、構造化データを記述するときに様々なデータを定義する単語集のようなもので、代表的なものではshema.orgがあります。
今回は、Googleが推奨しているJSON-LDと、shema.orgを使用した構造化データの書き方について解説していきます。
JSON-LDとは
JSON-LDは、他の2つのシンタックスとは異なり、scriptタグの中に記述していきます。
scriptタグ内であればHTML内のどこに記述しても良いので、他の2つのシンタックスがHTMLに直接記述していくことに比べて、JSON-LDではscriptタグ内に一箇所にまとめて記述することができ、ソース内がごちゃごちゃにならないという利点もあります。
JSON-LDの書き方
実際に例を挙げてマークアップしてみたいと思います。記述する情報は以下のとおりです。
------------------------------------------
株式会社みやあじよ「売上あげる、お手伝い」
https://myajo.net/

〒590-0958
大阪府堺市堺区宿院町西4丁目2-9 フォルテ宿院302
電話番号:050-6871-1052
営業時間:月~土9:00~18:00
------------------------------------------
この情報をJSON-LDで記述すると以下のようになります。
<script type="application/ld+json">
{
"@context" : "https://schema.org",
"@type" : "Organization",
"name" : "みやあじよ",
"description" : "売上あげる、お手伝い",
"url" : "会社のURL",
"logo": "画像のURL",
"telephone" : "+81-50-6871-1052",
"adress" : {
"@type" : "PostalAdress",
"streetAdress" :"宿院町西4丁目2-9 フォルテ宿院302",
"adressLocality" : "堺市堺区",
"adressRegion" : "大阪府",
"postalCode" : "590-0958",
"adressCountry" :"JP"
},
"openinghours" : "Mo, Tu, We, Th, Sa 9:00-18:00"
}
</script>書き方と記述した内容について解説していきます。
1.JSON-LD宣言文
一行目がJSON-LDの宣言文です。
その間にある{}の中をJSONオブジェクトといい、JSONオブジェクトはkeyとvalueによって構成されます。
<script type="application/ld+json">
{
ここに記述が入ります
}
</script>2.ボキャブラリーとプロパティ
keyはボキャブラリーで定義されているプロパティ(属性)のことで、valueは値を指します。
「"key": "value"」というように記述し、以下の例では@contextと@typeがkey、https://schema.orgとOrganizationがvalueになります。
@contextにはどのボキャブラリーを使用するか、@typeにはなんの記述をするのかを指します。
@typeは他にもArticle、WebSite、Personなどがあり、@typeのvalueで指定したタイプで利用できるプロパティを記述していきます。
今回は、@typeのvalueにshema.orgを指定しているので、どのようなプロパティがあ利用できるのかをhttps://schema.orgで確認します。
今回挙げている例では会社の情報(https://schema.org/Organization)をマークアップするので以下のようになります。
<script type="application/ld+json">
{
"@context" : "https://schema.org",
"@type" : "Organization",
}
</script>これで、JSON-LDで会社情報を記述する準備ができました。
3.会社情報のマークアップ(1)
会社情報を記述していきます。
"name"は名前、"telephone"は電話番号、"adress"は住所、というようにshema.orgで定義されているkeyを指定していきます。
"name"と"みやあじよ"、"telephone"+81-50-6871-1052"がそれぞれkeyとvalueの1セットとなります。
住所は"adress"のvalueにそのまま記述してもいいのですが、細かく指定していきたいので、"adress"に別の意味を持つオブジェクト埋め込みます。
"adress":{}というふうにvalueを{}で囲むことで、"@type":"PostalAdress"という別の意味をもつオブジェクトを埋め込むことができます。
この、valueに別のオブジェクトを埋め込むことを「エンベッティング」といいます。この{}の中に、同じように"adressLocality"や"adressRegion"の"key"を記述していくことで、より詳細の情報をマークアップしていくことができます。
<script type="application/ld+json">
{
"@context" : "https://schema.org",
"@type" : "Organization",
"name" : "みやあじよ",
"description" : "売上あげる、お手伝い",
"url" : "https://myajo.net",
"logo": "画像のURL",
"telephone" : "+81-50-6871-1052",
"adress" : {
"@type" : "PostalAdress",
"streetAdress" :"宿院町西4丁目2-9 フォルテ宿院302",
"adressLocality" : "堺市堺区",
"adressRegion" : "大阪府",
"postalCode" : "590-0958",
"adressCountry" :"JP"
}
}
</script>4.会社情報のマークアップ(2)
最後に、"openinghours"というkeyを使用して営業日と営業時間を記述していきます。
valueは少し長くなりますが以下のように記述します。
- 営業日は曜日の頭文字をカンマ(,)を使い組み合わせて記述
- 営業時間は営業開始時間と営業終了時間の間をハイフン(-)で結び記述
<script type="application/ld+json">
{
"@context" : "https://schema.org",
"@type" : "Organization",
"name" : "みやあじよ",
"description" : "売上あげる、お手伝い",
"url" : "https://myajo.net",
"logo": "画像のURL",
"telephone" : "+81-50-6871-1052",
"adress" : {
"@type" : "PostalAdress",
"streetAdress" :"宿院町西4丁目2-9 フォルテ宿院302",
"adressLocality" : "堺市堺区",
"adressRegion" : "大阪府",
"postalCode" : "590-0958",
"adressCountry" :"JP"
},
"openinghours" : "Mo, Tu, We, Th, Sa 9:00-18:00"
}
</script>これで会社情報の構造化データマークアップが完了しました。
構造化データテストツール
構造化データのマークアップが完了したら、構造化データテストツールを使ってマークアップが正しくできているか確認することができます。
構造化データテストツールを利用することで、簡単にマークアップを確認することができます。書き方が間違っているとエラーで教えてくれるので、必ず確認するようにしてください。
SearchConsole
構造化データをHTMLにマークアップし公開した後も、リッチスニペットが表示されているかや、マークアップした内容の管理をする必要があります。
そこで使うのがSearchConsoleです。
SearchConsoleを使うことで、構造化データの状況を見ることができ、定期的に監視することでGoogleの仕様変更などによって不具合がおきていないかを確認することができます。
まとめ
構造化データの導入には管理コストもかかりますが、JSON-LDであれば一箇所にまとめて記述できるため、比較的設置後の管理もしやすいです。
また、検索結果にリッチスニペットが表示されるようになれば、サイトへの導入の向上にも大きく貢献するはずです。
ぜひ、この記事を参考に構造化データの導入を考えてみてください。







